
A new piece of research has recently been dropped on a Github page titled Doxer. The research includes a completely original algorithm that allows one to determine the identity of an author simply by way of analyzing the unique occurrence of words. As a way of full disclosure, I am the author of the Github page and am very excited to share this original finding with you all.
The main core of the program is made with Python and undergoes what is known as a unique word analysis. This means that the number of unique words of two separate authors is counted and then compared to the unique words that they share with other authors in a corpus (i.e. collection of texts). The author with the highest ratio of unique words with the query text compared to the average number of unique words with the corpus texts becomes the winner.
By way of example, the Github page provides a toy example to make the process clearer. Let’s say that we are trying to identify the authorship of Satoshi and have four candidate authors named Gavin, Craig, Adam Back, and Michael Brown (a.k.a. knightMB). Let’s say that Gavin and Satoshi share 50 unique words that no other author in the corpus shares. Let’s further say that Gavin shares 20 words in common with Craig, 20 words in common with Adam Back, and 20 words in common with Michael Brown. The final score for Gavin will thus be 50 / ( (20+20+20 / 3) ) giving him a score of 50/20. This process will be repeated for each candidate text and the candidate with the highest score wins.
This algorithm is somewhat highly interpretable making it a fitting example of a Data Mining algorithm. My supervisor in Data Mining once taught me that the difference between Machine Learning and Data Mining is that the former has a focus on merely getting the result while the latter is more-so focused on creating interpretable materials that can be read by humans.
The Github page has graciously included a dataset of all the substantial profiles between the IDs of 1 and 2000 on the Bitcoin Talk Forum. This specific dataset was used to create an experimental setup where Satoshi’s forum posts could be compared with other forum posters, controlling for the genre and context of the materials. I hope that these freely available materials will encourage other researchers and hobbyists to try and extend the field of Stylometry (i.e. authorship attribution) and try out their own ideas.
By way of proving that the algorithm Doxer is more than just a fanciful idea, the author included 3 benchmarks in English, Russian, and Polish. Doxer got around 85% accuracy on each benchmark despite them all being in a different language. But as you may be anticipating, the exciting part is yet to come when I use these newly acquired tools to identify Satoshi himself.
Yet a quick word on making the algorithm even more accurate, the author created a Random Forest on 200,000 instances from Gutenberg and 80,000 instances from a Kindle collection. The forest was built on an Amazon EC2 and included both word and character grams. The forest was built in order to reduce the list of around 600 Bitcoin Talk Forum profiles down to a more manageable level. An unexpected finding by the author was that the Kindle dataset was more accurate than the Gutenberg dataset in classifying modern texts. He reasoned that older texts work better on older textual problems and newer texts understandably work better on newer textual problems.
And by way of a long introduction, I’m sure, I’ll finally get to the main findings of the research article. A link to the Github repository will be left at the end of this article just in case you want to check it out for yourself (which I highly recommend). I found that 9 out of 13 Forest models classified Gavin Andresen (ID = 224), previously chief scientist of the Bitcoin project, and Lachesis (ID = 237), early Bitcoin developer and successful researcher in his own right, as Satoshi. The top profiles classified as Satoshi (including 3 other profiles) by the Forest were then analyzed with Doxer, covering 4-10 character grams and 1-10 word grams using a skip-gram model to make them scalable. The end result was nearly unanimous with Gavin Andresen being classified as Satoshi Nakamoto.
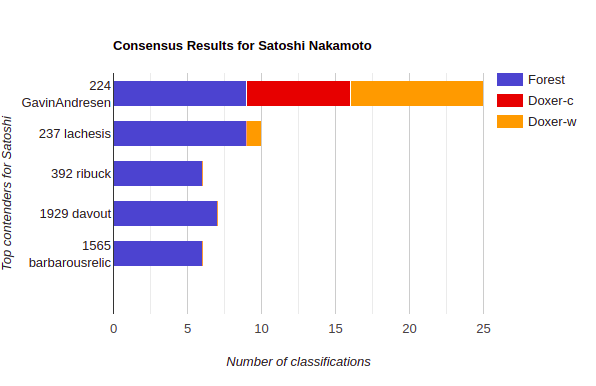
The results seem quite definite, yet I think it still worth mentioning the runners-up and other profiles that I’ve noticed have a similar writing style to Satoshi. Lachesis of course should be included in every analysis of Stylometry. He tied after all with Gavin on the Forest models. Coming in third, in my tentative opinion, I would place JGarzik (ID = 541) as next in line because Doxer alone stumbles across his style many times. There are also two other profiles that were not classified by the forest that I think should be considered and they include Laszlo (ID = 143) and knightMB (ID = 345). One bought a very expensive pizza and the other wrote a whitepaper titled TimeKoin. These two are less likely as they were not included in the Forest classification, yet I still think they are worth analyzing due to their similar style with Doxer alone.
But what one must take rather seriously is the interesting occurrence of the phrase ‘back-of-the-envelope’ in both Gavin’s and Satoshi’s writings. I have pointed out this strange occurrence many times in the past only to be brushed off with the common reply that many people in the world use this phrase. But I must say that if you use a grep -l back-of-the-envelope * command in the folder of the Bitcoin forum posts, you will find that only three people used this phrase in the entire forum posts between IDs 1 and 2000. The first two are as you may guess Satoshi and Gavin, while the third person is a lesser-known poster who doesn’t show up on any of the stylometry measures. Sure, this phrase may be used across the world, but how many people in the Bitcoin project (during the early days) used this peculiar phrase? It just so happens that Gavin and Satoshi used the phrase before their supposed first meeting.
Another takeaway from this research page is that there is an interesting similarity between the phrase back-of-the-envelope and other well-known Bitcoin phrases such as proof-of-work and proof-of-stake. There is a long list of these idiosyncratic phrases on the Github page for you to observe yourself. It is near as if Gavin’s fingerprints are left all over the Bitcoin Glossary itself!
There was quite recently a documentary made on the identity of Satoshi. The main premise was that Adam Back authored the whitepaper. For this reason, I went out of my way to add Adam Back’s profile to the current textual corpus even though he was way out of the 2,000 ID limit that I employed. I found no similarity whatsoever between Adam Back and Satoshi from a Stylometry perspective. The documentary did make an interesting finding of the double space after full stops used by Satoshi. My simple response to this is that in the early days, on the Bitcoin forum, Gavin used double spaces at the end of full stops too.
And just to recap on the findings thus far, Gavin Andresen, former Chief Scientist of the Bitcoin project, has been classified as having the same writing style as Satoshi Nakamoto. Great care has been taken so as to take the genre into account by creating analysis over similar texts. An entirely original algorithm has been invented to approach this problem with the specific goal of unmasking Satoshi. The project is completely transparent so that other researchers can check the results for themselves and maybe even create their own algorithms. I have thoroughly enjoyed researching this topic and hope that other people can take joy in understanding and extending my findings.
The Doxer program can be found at this address: https://github.com/goldmonkey21/doxer
Source: Read Full Article